shift
会说 → 会做
focus
执行系统
过去两年大家比的是模型能力;最近半年开始比执行闭环、自动处理、消息直连和任务完成率。

结论 OpenClaw 出现在这个时间点,不是偶然,而是“执行型 AI”浪潮的一个典型产物。
Clawdbot 初始发布,项目正式出现。
先改名 Moltbot,随后再次更名为 OpenClaw。
Moltbook 事件和 “agent 社交网络” 话题推动全球破圈。
Peter Steinberger 宣布加入 OpenAI,同时强调项目保持开源并转向基金会结构。
腾讯、地方政府、云平台和社区工具多线推进,国内进入大众传播阶段。


这条时间线要帮学员建立一个判断:OpenClaw 不是孤立的新工具,而是全球 agent 浪潮和国内平台化推进的交叉点。
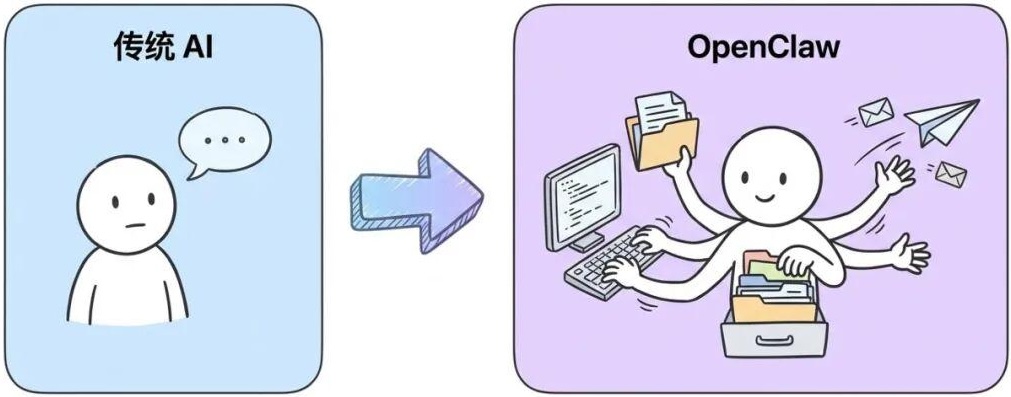
飞书、Telegram、Discord、微信等,都可以只是它的通信端口。
真正做事的环境是你的电脑或服务器,而不是一个网页聊天框。
长期记忆、Skills、自动化、定时任务、事件驱动,让它持续工作。
一句话 你其实是在跟自己的电脑讲话,然后让它替你把事情做完、再回来汇报。
| 比较维度 | 聊天模型 | OpenClaw |
|---|---|---|
| 核心问题 | 怎么回答 | 怎么执行 |
| 交互方式 | 问一句答一句 | 你说它干,干完汇报 |
| 持续性 | 会话为主 | 可长期运行 |
封装版的本质,是在开源 OpenClaw 之上帮用户预装、简化配置、再包一层产品入口。

封装版做快速验证,自部署做正式使用。很多人的真实路径,就是先装封装版体验,再迁移到自部署。
| 维度 | 封装版 | 自部署 |
|---|---|---|
| 上手速度 | 快 | 中等 |
| 可控程度 | 低 | 高 |
| 数据隐私 | 依赖封装方 | 自己掌控 |
| 迁移成本 | 常常不透明 | 配置可导出 |
| 适合人群 | 先跑起来的人 | 重视隐私和定制的人 |
完全没有命令行经验,或者你当前目标只是先看看效果。
你在意数据安全、长期使用、接自己的模型和通信渠道。
先让大家“装起来并跑通”,再谈更复杂的优化和迁移。

openclaw onboard。openclaw status / openclaw health。curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboard
openclaw status
openclaw health
22 端口,先用 SSH 连通。ssh root@你的公网IP
curl -fsSL https://openclaw.ai/install.sh | bash
openclaw onboardopenclaw 命令能执行openclaw onboard 能正常跑完status / health 无明显报错课堂目标不是替学员选模型,而是让学员以后自己会选。
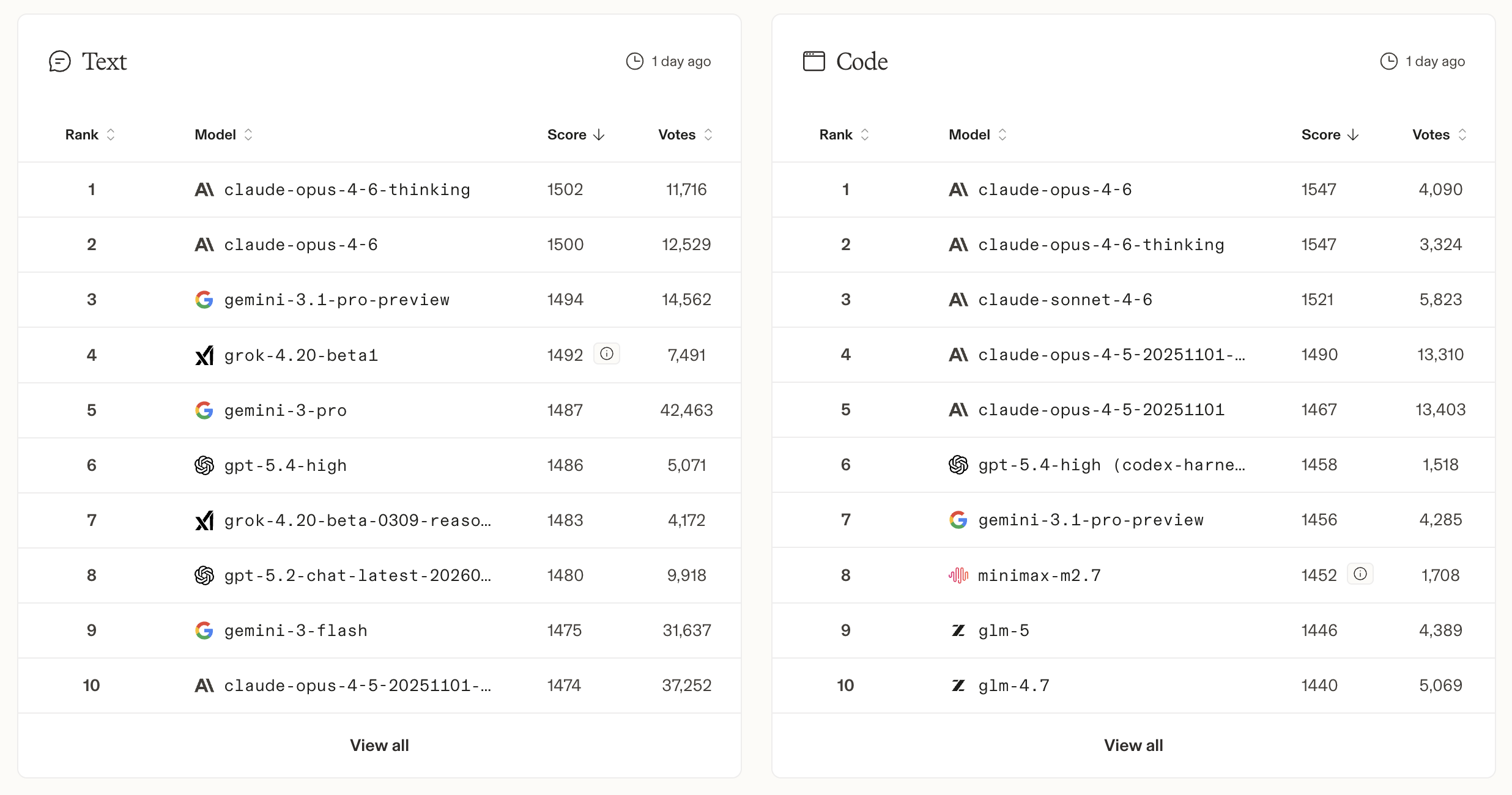
用 Arena Leaderboard 一类公开榜单建立性能参考,不要凭感觉选模型。
决策双轨 先确定你追求的是“表现上限”还是“预算稳定”,再决定具体模型和付费方式。
课堂总括 以前是“把龙虾接进飞书里”;现在是“让龙虾在飞书里真正长出手脚”。
第一堂课先把最短链路讲清楚:装插件、做授权、确认机器人已经能正常回应。
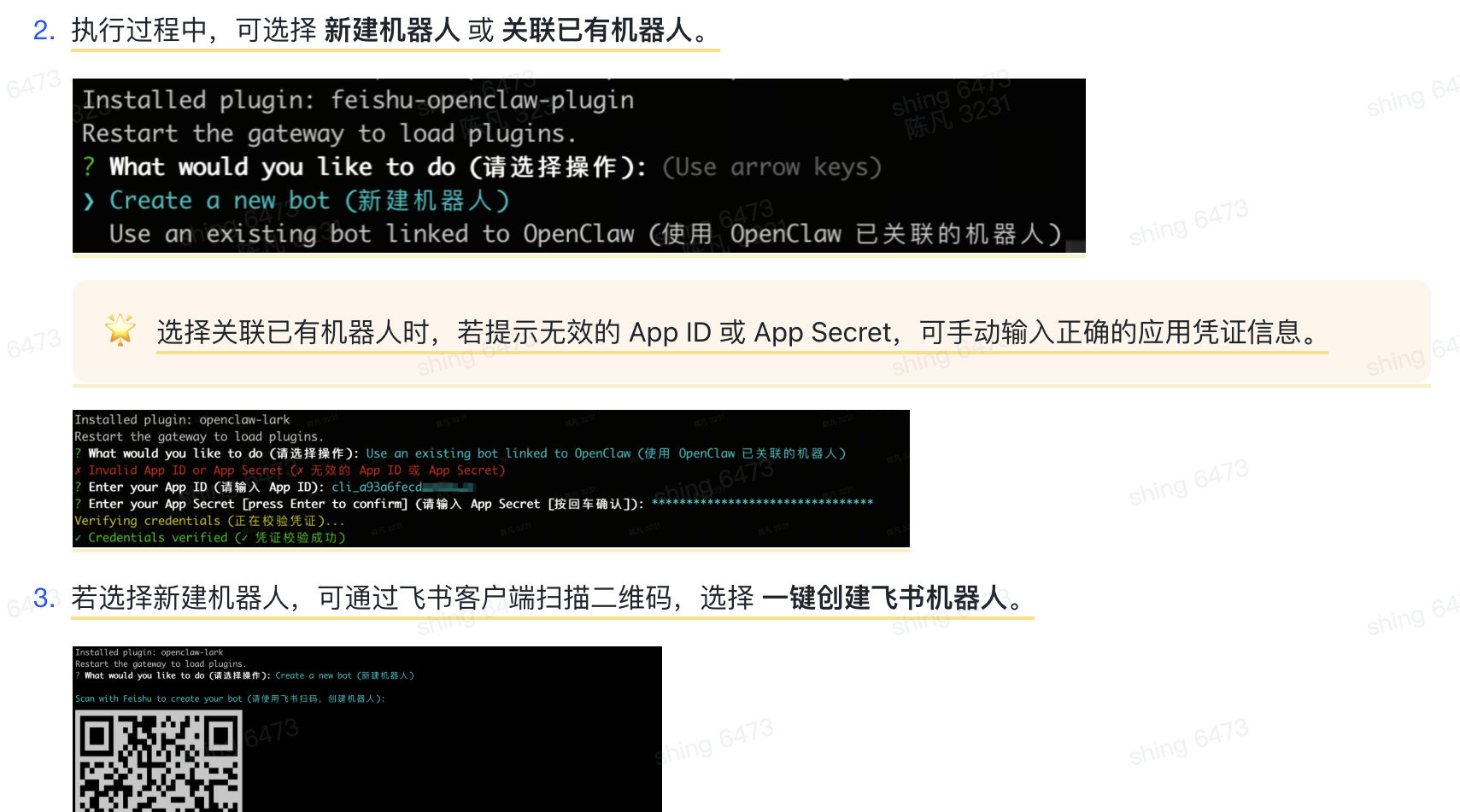
终端执行安装命令。
在飞书对话里发送一条消息。
执行 /feishu auth 完成授权。
让它列出新飞书插件的能力。
执行 /feishu start,确认机器人已正常接入。
npx -y @larksuite/openclaw-lark install/feishu auth
/feishu start